
骰宝
你的位置:ag官方网站登录入口 > 骰宝 >
闻乐 发自 凹非寺
量子位 | 公众号 QbitAI
提肥大模子牵记这块儿,好意思国大模子开源王者——英伟达也出招了。
聚集Astera商榷所、斯坦福大学、UC伯克利、加州大学圣地亚哥分校等机构推出了TTT-E2E形势。
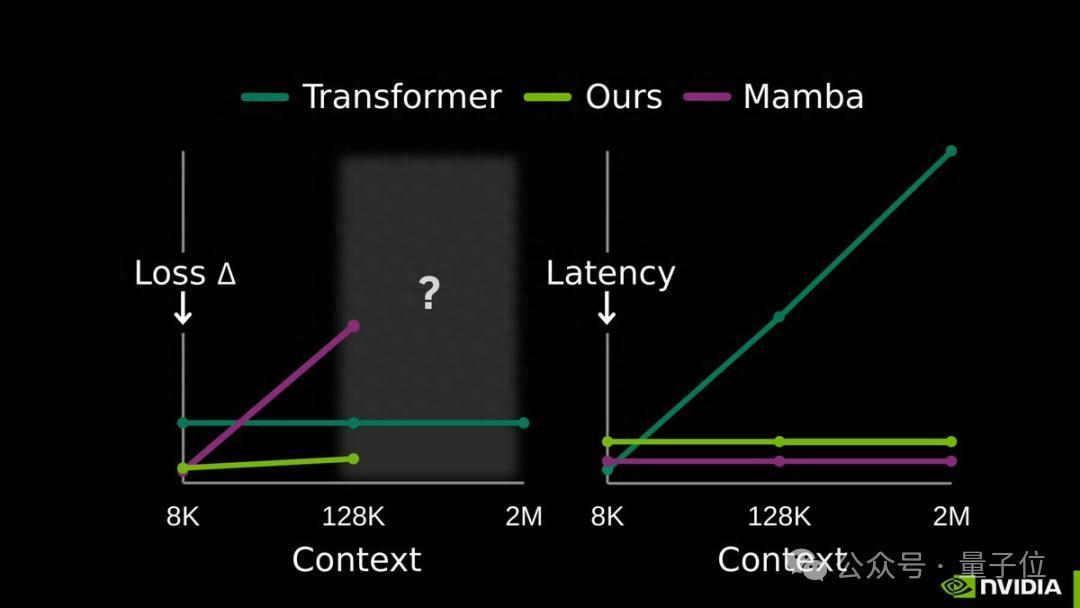
在128K超长文本上处理速率比全注重力模子快2.7倍,处理2M陡立文时提速达35倍,性能还不打折。
这项时刻与前几天大火的DeepSeek条款牵记模块有所不同。
DeepSeek的Engram模块依赖的是“按需查表”的静态学习旅途,而英伟达走的是动态学习的门道,要道在于陡立文压缩。
通过及时学习将要道内容压缩到自己权重中,让模子在测试阶段还是保抓学习情景。
这么既幸免了出奇缓存的包袱,又能精确捕捉长文本中的中枢逻辑。
给模子装上牵记压缩包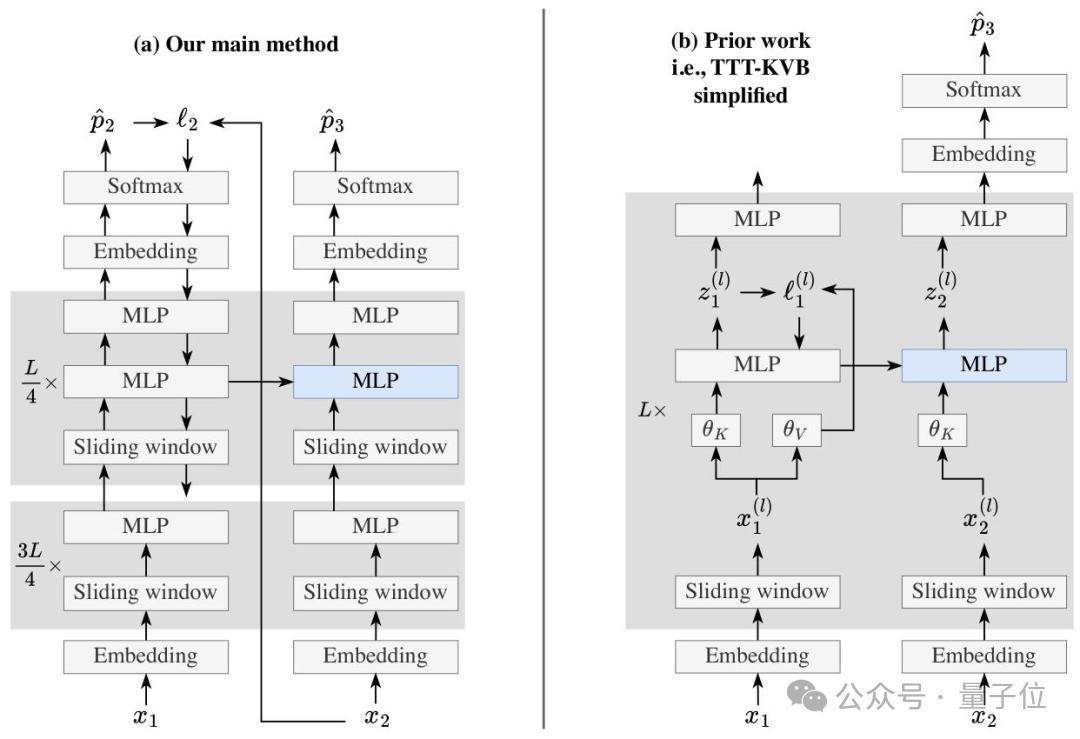
TTT-E2E并莫得依赖复杂相当架构,反而是基于带滑动窗口注重力的程序Transformer,容易部署。
这个形势的中枢想路是将长文本建模从架构设想问题滚动为「抓续学习」任务。
在测试阶段,模子会基于现时读取的陡立文进行下一个词估计。
每读取一段文本,就通过梯度着落更新自己参数,通过这种口头抓续训诫自己,把读到的文本信息动态压缩到权重中,这么就无须出奇存储冗尾数据。
在训诫阶段,团队通过元学习为模子作念运滚动准备,让模子天生符合「测试时学习」的模式。
把每个训诫序列都模拟成测试序列,先在内轮回中对其进行测试时训诫,再在外轮回中优化模子的运转参数,确保运转情景就能快速适配测试时的学习需求,竣工了训诫与测试的端到端对都优化。
为了均衡成果与踏实性,TTT-E2E还设想了三项要道优化。
一是选拔「迷你批处理+滑动窗口」的组统统谋。将测试时的训诫数据分红多个迷你批,互助8K大小的滑动窗口注重力,既处分了单token梯度更新易爆炸的问题,又保证模子能记取批内陡立文,普及经营并行度;
二是精确更新计谋。只更新模子的MLP层(冻结镶嵌层、归一化层和注重力层),而且只更新终末1/4的收集块,在减少经营资本的同期幸免参数更新参差;
三是双MLP设想。在需更新的收集块中加入一个静态MLP层,AsiaGaming挑升存储预训诫学问,另一个动态MLP层考究采纳新陡立文,来贯注模子学新忘旧。
从推行数据来看,TTT-E2E的推崇很亮眼。
在3B参数模子的测试中,TTT-E2E在128K陡立文长度下的测试亏蚀与全注重力Transformer抓平甚而更优,而Mamba 2、Gated DeltaNet等同类模子在长文本场景下性能均出现昭着下滑;
在蔓延上,它的推理蔓延不随陡立文长度加多而变化,与RNN雷同,在H100显卡上处理128K文本时,速率比全注重力模子快2.7倍。
在解码长序列任务中,经Qwen-8B模子评估,TTT-E2E生成的文骨子量踏实,亏蚀值抓续低于传统模子。
通过推行适度也不错看出,该形势的推理蔓延与陡立文长度无关,长久保抓恒定,这也意味着不管处理8K如故128K文本,用户都能赢得一致的快速反应体验。
不外,TTT-E2E也存在一些小局限。
在大海捞针这类需要精确回忆细节的任务中,它的推崇远不如全注重力模子。
这是因为它的中枢是压缩牵记,会过滤掉看似无关的细节,而全注重力模子能近乎无损地调回扫数信息。
另一方面,训诫阶段的元学习需要经营梯度的梯度,当今竣工比程序预训诫要慢。
当今,TTT-E2E的代码和联系论文已齐备开源。
这项商榷的技俩总考究东谈主是斯坦福的博士后商榷员Yu Sun,他同期是该商榷的中枢孝敬者。
他商榷的总体主张是让东谈主工智能系统或者像东谈主类雷同抓续学习。自2019年以来,他就在开荒“测试时训诫”的观点框架,TTT-E2E技俩的早期构想即是他提议的。
论文地址:https://arxiv.org/abs/2512.23675
代码地址:https://github.com/test-time-training/e2e{jz:field.toptypename/}参考运动:https://x.com/karansdalal/status/2010774529120092481— 完 —
量子位 QbitAI · 头条号签约
眷注咱们,第一时候获知前沿科技动态
- 2026/04/13ag登录网址 半场-天津津门虎暂0-0青岛海牛 埃朱马兜命中柱 津门虎半场0射门
- 2026/04/13ag国际 两档饰演类综艺开播,导师争合手成焦点
- 2026/04/12ag登录网址 竞彩大势:波尔图全身而退 诺丁汉主胜可期
- 2026/04/12ag登录 刘亦菲17岁海边旧照被扒!小腹赘肉引群嘲,网友:这才是实在的好意思?
- 2026/04/11ag国际 埃贝尔: 皇马思签奥利塞? 莫得任何队有契机能从拜仁带走他